
2024.07.28 - [Database/MySQL] - [MySQL] 기본 SQL 정리 (1) (DDL, DCL)
[MySQL] 기본 SQL 정리 (1) (DDL, DCL)
0. SQLStructured Query Language관계형 DB 활용을 위한 표준 언어📌 SQL 작성 규칙SQL문법 : 대문자 작성 권장 테이블명속성명 : 소문자 작성 권장 이름 : 의미가 잘 드러나게 작성, 여러 단어 혼합 시 “_”
blogan99.tistory.com
1. DML
- SELECT (데이터 검색)
- INSERT (데이터 삽입)
- UPDATE (데이터 변경)
- DELETE (데이터 삭제)
1-1. 데이터 검색
SELECT [DISTINCT | ALL] 열_리스트
FROM 테이블_리스트
[WHERE 검색_조건식]
[GROUP BY 그룹_기준열_리스트]
[HAVING 그룹_조건식]
[ORDER BY 정렬_기준열 [ASC | DESC] ];
-- ex
-- 1. 테이블의 특정 열 검색
SELECT title, author FROM book;
-- 2. 테이블의 모든 열 검색
SELECT * FROM book;
-- 3. 중복 행 제거
SELECT DISTINCT title, author FROM book;- WHERE : 참 또는 거짓 판별 가능한 하나 이상의 검색 조건식 명세
📌
- 비교연산자 : =, <>, !=, <, <=, >, >=
- 논리연산자 : NOT, ! > AND, && > OR, ||
비교연산자 > 논리연산자
- 문자나 날짜값 ⇒ ‘상수값’ 형태로 작은 따옴표(’) 로 묶음
- 기타연산자 : BETWEEN, IN, NOT IN
- 순서화 검색 : ORDER BY
- 정렬 조건이 여러개 → 정렬 우선순위를 순서로 반영해야함!
- 검색 결과 제한 : LIMIT
LIMIT (시작_인덱스,) 반환_행_개수
-- ex
SELECT * FROM book WHERE title = '책1';
SELECT * FROM score WHERE korean >= 90 OR math > 80;
SELECT name, grade
FROM student
WHERE (grade >= 1 AND grade <=3) OR NOT (class='class1');
SELECT * FROM score WHERE math BETWEEN 80 AND 90;
SELECT * FROM student
ORDER BY 학년 ASC, 이름 DESC;
LIMIT 5, 3;- LIKE : 유사한 값 조회
- _ 와일드카드 : 문자열 중 특정 위치에 1개의 모든 문자 허용
- % 와일드카드 : 문자열 중 임의 위치에 0개 이상의 모든 문자 허용
- null 값 검색
- IS NULL 혹은 IS NOT NULL 사용!
- null 값에 대해서는 = 비교 연산자 사용 불가능하기 때문임
- GROUP BY : 개별 행이 아닌 행 그룹에 대한 검색
특정 열의 값이 같은 행들끼리 그룹을 만듦- HAVING : 그룹에 대한 조건 명세
⇒ GROUP BY절 통해 생성된 새로운 그룹에서도 특정 조건을 만족하는 그룹만으로 검색 조건 제한
- HAVING : 그룹에 대한 조건 명세
SELECT [DISTINCT | ALL] 열_리스트
FROM 테이블_리스트
[GROUP BY 그룹_기준열_리스트]
[HAVING 그룹_조건식];
-- ex
-- 1. 전체 학생의 성별 최고 나이와 최저 나이 검색
SELECT gender, MAX(age) AS '최고 나이', MIN(age) AS '최저 나이'
FROM student
GROUP BY gender;
-- 2. 각 학년별로 10명 이상의 학생을 갖는 학년에 대해서만 학년별 학생수 검색
SELECT grade, COUNT(*) AS '학년별 학생수'
FROM student
GROUP BY grade
HAVING COUNT(*) >= 10;
1-1-1. 집합 연산자
- UNION (합집합)
- 컬럼의 수와 데이터 형식이 일치한 경우에만 사용 가능!
- 자동으로 중복 행 제거! (이 과정에서 정렬이 발생, 올바른 정렬 하려면 ORDER BY 사용할 것!)
-- ex
SELECT grade FROM student WHERE gender = 'M'
UNION
SELECT grade FROM class WHERE score = 100;- UNION ALL (합집합, 중복 허용)
- UNION과 동일하지만 중복 제거 x, 정렬 x
- INTERSECT (교집합) ⇒ MySQL에서는 지원 x! (Oracle, Maria DB 는 지원)
- 두 테이블에 대해서 겹치는 부분 추출
- 중복 행 제거!
SELECT grade FROM student1
INTERSECT
SELECT grader FROM student2;- EXCEPT (차집합) ⇒ MySQL에서는 지원 x!
1-1-2. 서브 쿼리 (subquery)
- 질의문 안에 중첩되어 포함된 또 다른 SELECT 문
- 실행 순서 : 가장 안 쪽 서브쿼리 > 다음 안 쪽 서브쿼리 > … > 메인 쿼리
📌 서브 쿼리 주의사항
1. 괄호와 함께 사용되어야 함
2. 서브 쿼리 내부에는 ORDER BY 절 사용 불가
3. 서브 쿼리는 연산자의 오른쪽에 사용되어야 함
4. 오로지 SELECT 문으로만 작성 가능
-- ex
-- 1. Inner Query 1개 (부 질의문)
SELECT name FROM student
WHERE id IN (SELECT id FROM class
WHERE class_id IN ('c001', 'c002', 'c003');
-- 2. Inner Query 2개 (중첩 부 질의문)
SELECT 이름 FROM 학생
WHERE 학번 IN (SELECT 학번 FROM 수강
WHERE 과목번호 = (SELECT 과목번호 FROM 과목
WHERE 과목이름 = '데이터베이스'));
1-1-3. 다중 행 연산자
- IN : 서브쿼리 결과에 존재하는 값들 중 하나라도 일치하는지 여부
-- IN ex
SELECT name FROM student
WHERE age IN (20, 21, 24);- EXISTS : 서브쿼리 결과 값이 존재하는지 여부
-- EXISTS ex
SELECT name FROM student
WHERE EXISTS ( SELECT * FROM class
WHERE class.student_id = student.id
AND class_name = '데이터베이스');- ALL : 서브쿼리 결과에 존재하는 모든 값 들에 대해 조건이 만족하는지 여부
-- ALL ex
-- 개발 팀 소속 모든 직원들 급여보다 급여가 크거나 같은 직원 이름 출력
SELECT name FROM employee
WHERE salary >= ALL (SELECT salary
FROM employee
WHERE department_id = 1);- ANY : 서브쿼리 결과에 존재하는 값들 중 하나 이상 만족하는지 여부
-- ANY ex
-- 개발 팀 소속 임의의 직원들 급여보다 급여가 크거나 같은 직원 이름 출력
SELECT name FROM employee
WHERE salary >= ANY (SELECT salary
FROM employee
WHERE department_id = 1);
📌 IN vs EXISTS
- IN과 EXISTS 모두 서브쿼리 사용할 때 주로 사용, 동작 방식과 용도가 다름
- IN : 특정 값이 목록에 포함되어 있는지 확인할 때 사용
- 서브쿼리가 반환하는 결과의 모든값 비교
⇒ 서브쿼리가 반환하는 값의 개수에 따라 성능 영향!
- EXISTS : 서브쿼리가 결과를 반환하는지 여부 확인할 때 사용
- 서브쿼리가 하나 이상의 행을 반환하는지 체크
⇒ 서브쿼리가 반환하는 데이터의 수에 따라 성능 영향 x!! 그냥 결과 존재하는지 여부만 체크
정리) EXISTS 가 성능면에서 효율적일 수 있음
(특히 서브쿼리가 큰 경우 EXISTS 는 빠르게 종료 가능하기 때문)
1-1-4. 조인 연산자 JOIN
- 둘 이상의 테이블로부터 연관된 행들의 결합을 통해서 검색 결과 생성
- 방법 1) WHERE 조인_조건식 AND 검색_조건식
- 방법 2) [INNER] JOINT 조인_대상_테이블 ON 조인_조건식
-- 조인문 방법 1
SELECT 열_리스트
FROM 조인_테이블_리스트
WHERE 조인_조건식 AND 검색_조건식
-- 조인문 방법 2
SELECT 열_리스트
FROM 조인_테이블1 [INNER] JOIN 조인_테이블2 ON 조인_조건식
WHERE 검색_조건식
- 크로스 조인 (CROSS JOIN)
- 카티션 프로덕트 연산 수행 결과
SELECT * FROM 학생, 수강; SELECT * FROM 학생 CROSS JOIN 수강; - 셀프 조인 (self join)
- 같은 테이블 내에서 조인
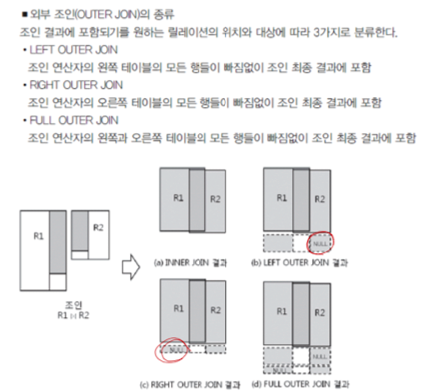
-- 주소가 같은 학생들의 이름을 쌍으로 검색, 이때 첫번째 학생이 두번째 학생보다 학년이 높도록 설정 SELECT s1.이름, s2.이름 FROM 학생 s1 JOIN 학생 s2 ON s1.주소 = s2.주소 WHERE s1.학년 > s2.학년; - 외부 조인 (OUTER JOIN)
- LEFT [OUTER] JOIN, RIGHT [OUTER] JOIN, FULL OUTER JOIN
1-2. 데이터 삽입
INSERT INTO 테이블_이름 [(열_리스트)]
VALUES (값_리스트);
-- ex
INSERT INTO book (name, author)
VALUES ('어린왕자', '생택쥐베리');
INSERT INTO book
VALUES ('책1', '저자1', 2024, 20000);- 기존 테이블의 열_리스트 그대로 순서 유지하면서 값을 삽입할 때는 (열_리스트) 생략 가능!
📌 복제 테이블 생성
CREATE TABLE 새로운_테이블이름 AS (SELECT * FROM 기존_테이블이름);
⇒ 데이터는 복제됨, 그러나 키, 제약 조건 등은 복제 x !!
1-3. 데이터 변경
UPDATE 테이블_이름
SET 열_이름 = 산술식
[WHERE 수정_조건식];
-- ex
UPDATE student
SET grade = 3
WHERE name like '%길동';
UPDATE student
SET grade = grade+1, age = 24
WHERE name = '홍길동';
1-4. 데이터 삭제
DELETE FROM 테이블_이름
[WHERE 삭제_조건식];
-- ex
DELETE FROM student WHERE name = '홍길동';
DELETE FROM student; -- 테이블의 모든 데이터 삭제됨- WHERE 삭제_조건식을 생략하면 테이블 내의 모든 데이터 삭제됨!
2. 집계 함수 (Aggregate Function)
- COUNT(열_이름) : 특정 열 값의 개수 or 행의 개수
COUNT(*) COUNT(열_이름) COUNT(DISTINCT 열_이름) NULL 값 허용 여부 O X X 중복 값 허용 여부 O O X - MAX(열_이름) : 특정 열 값 중 최댓값
- MIN(열_이름) : 특정 열 값 중 최솟값
- SUM(열_이름) : 특정 열 값의 합계
- AVG(열_이름) : 특정 열 값의 평균
⇒ SUM(), AVG() 는 숫자형 열에만 적용 가능!
⇒ AS 통해서 별칭 부여 가능 (생략 가능)
SELECT AVG(age) AS '남학생 평균나이'
FROM student
WHERE gender = '남';
'Database > MySQL' 카테고리의 다른 글
| [MySQL] 뷰 (View), 인덱스 (Index) (0) | 2024.07.28 |
|---|---|
| [MySQL] 기본 SQL 정리 (1) (DDL, DCL) (0) | 2024.07.28 |
| [MySQL] ERROR 1819 (HY000): Your password does not satisfy the current policy requirements 에러 해결 (0) | 2023.12.12 |
| [MySQL] MySQL 완전 삭제 후 재설치 (Mac OS) (0) | 2023.12.12 |